What is Data?
In simple words data can be facts related to any object in consideration.
For example your name, age, height, weight, etc are some data related to you.
A picture, number, image , file , etc can also be considered data.
What is a Database?
Database is a systematic collection of data. Databases support storage and manipulation of data. Databases make data management easy. Let's discuss few examples.
An online telephone directory would definitely use database to store data pertaining to people, phone numbers, other contact details, etc.
Your electricity service provider is obviously using a database to manage billing, client related issues, to handle fault data, etc.
Let's also consider the facebook. It needs to store, manipulate and present data related to members, their friends, member activities, messages, advertisements and lot more.
We can provide countless number of examples for usage of databases.
What is a Database Management System (DBMS)?
Database Management System (DBMS) is a collection of programs which enables its users to access database, manipulate data, reporting / representation of data.
It also helps to control access to the database.
Database Management Systems are not a new concept and as such had been first implemented in 1960s.
Note: Charles Bachmen's Integrated Data Store (IDS) is said to be the first DBMS in history.

DBMS Database Models
Hierarchical Model
Network Model

Entity-relationship Model

Relational Model



Some commands /operations of DBMS
i. Create Table Basics
A relational database system contains one or more objects called tables. The data or information for the database are stored in these tables. Tables are uniquely identified by their names and are comprised of columns and rows. Columns contain the column name, data type, and any other attributes for the column. Rows contain the records or data for the columns. Here is a sample table called "weather".
City, state, high, and low are the columns. The rows contain the data for this table:
Example:
ii. Selecting Data
The select statement is used to query the database and retrieve selected data that match the criteria that you specify. Here is the format of a simple select statement:
The table name that follows the keyword from specifies the table that will be queried to retrieve the desired results.
The where clause (optional) specifies which data values or rows will be returned or displayed, based on the criteria described after the keyword where.
Conditional selections used in the where clause:
iii. Inserting into a Table
The insert statement is used to insert or add a row of data into the table.
To insert records into a table, enter the key words insert into followed by the table name, followed by an open parenthesis, followed by a list of column names separated by commas, followed by a closing parenthesis, followed by the keyword values, followed by the list of values enclosed in parenthesis. The values that you enter will be held in the rows and they will match up with the column names that you specify. Strings should be enclosed in single quotes, and numbers should not.
Example:
iv. Updating Records
The update statement is used to update or change records that match a specified criteria. This is accomplished by carefully constructing a where clause.
v. Deleting Records
The delete statement is used to delete records or rows from the table.
vi. Drop a Table
The drop table command is used to delete a table and all rows in the table.
To delete an entire table including all of its rows, issue the drop table command followed by the tablename. drop table is different from deleting all of the records in the table. Deleting all of the records in the table leaves the table including column and constraint information. Dropping the table removes the table definition as well as all of its rows.
Data Security
What is Data Security?
Why Data Security?
Data Security Solutions
What is Data Warehousing?
Types of Data Warehouse

Business understanding:
Data understanding:
Data preparation:
Data transformation:
Modelling
Evaluation:
Deployment:
Data mining Examples:
Benefits of Data Mining:
Disadvantages of Data Mining

Bit: A single binary digit 0 and 1
Byte: Collection of bits
Record: Multiple related Field and characters.
File: Multiple related Record
Database: Multiple related File
Database models and types.
DBMS Database Models
A Database model defines the logical design and structure of a database and defines how data will be stored, accessed and updated in a database management system. While the Relational Model is the most widely used database model, there are other models too:
- Hierarchical Model
- Network Model
- Entity-relationship Model
- Relational Model
- Object-oriented database mode
Hierarchical Model
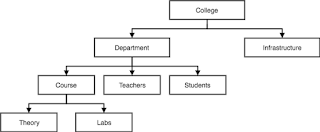
This database model organises data into a tree-like-structure, with a single root, to which all the other data is linked. The heirarchy starts from the Root data, and expands like a tree, adding child nodes to the parent nodes.
In this model, a child node will only have a single parent node.
This model efficiently describes many real-world relationships like index of a book, recipes etc.
In hierarchical model, data is organised into tree-like structure with one one-to-many relationship between two different types of data, for example, one department can have many courses, many professors and of-course many students.

Network Model
This is an extension of the Hierarchical model. In this model data is organised more like a graph, and are allowed to have more than one parent node.
In this database model data is more related as more relationships are established in this database model. Also, as the data is more related, hence accessing the data is also easier and fast. This database model was used to map many-to-many data relationships.
This was the most widely used database model, before Relational Model was introduced.
Entity-relationship Model
In this database model, relationships are created by dividing object of interest into entity and its characteristics into attributes.
Different entities are related using relationships.
E-R Models are defined to represent the relationships into pictorial form to make it easier for different stakeholders to understand.
This model is good to design a database, which can then be turned into tables in relational model(explained below).
Let's take an example, If we have to design a School Database, then Student will be an entity with attributes name, age, address etc. As Address is generally complex, it can be another entity with attributes street name, pincode, city etc, and there will be a relationship between them.
Relational Model
In this model, data is organized in two-dimensional tables and the relationship is maintained by storing a common field.
This model was introduced by E.F Codd in 1970, and since then it has been the most widely used database model, in fact, we can say the only database model used around the world.
The basic structure of data in the relational model is tables. All the information related to a particular type is stored in rows of that table.
Hence, tables are also known as relations in relational model.
In the coming table we will learn how to design tables, normalize them to reduce data redundancy and how to use Structured Query language to access data from tables.

Object-oriented database model
Object-oriented databases (OODB) are databases that represent data in the form of objects and classes. In object-oriented terminology, an object is a real-world entity, and a class is a collection of objects. Object-oriented databases follow the fundamental principles of object-oriented programming (OOP). The combination of relational model features (concurrency, transaction, and recovery) with object-oriented principles results in an object-oriented database model.
The object-oriented database model (OODBM) is an alternative implementation to that of a relational model. An object-oriented database is similar in principle to an object-oriented programming language. An object-oriented database management system is a hybrid application that uses a combination of object-oriented and relational database principles to process data. That said, we can use the following formula to outline the OODBM:
Object-Oriented Programming + Relational Database Features = Object-Oriented Database Model
The figure below outlines the object-oriented database model along with its principles and features.


SQL
SQL stands for “Structured Query Language”. SQL is used to communicate with a database. According to ANSI (American National Standards Institute), it is the standard language for relational database management systems.
SQL statements are used to perform tasks such as update data on a database, or retrieve data from a database. Some common relational database management systems that use SQL are: Oracle, Sybase, Microsoft SQL Server, Access, Ingres, etc.
The standard SQL commands such as "create", "select", "insert", "update", "delete", and "Drop" can be used to accomplish almost everything that one needs to do with a database.
Some commands /operations of DBMS
i. Create Table Basics
A relational database system contains one or more objects called tables. The data or information for the database are stored in these tables. Tables are uniquely identified by their names and are comprised of columns and rows. Columns contain the column name, data type, and any other attributes for the column. Rows contain the records or data for the columns. Here is a sample table called "weather".City, state, high, and low are the columns. The rows contain the data for this table:
Example:
create table employee(first varchar(15), last varchar(20), age number(3), address varchar(30), city varchar(20),state varchar(20));
ii. Selecting Data
The select statement is used to query the database and retrieve selected data that match the criteria that you specify. Here is the format of a simple select statement:select "column" [,"column2",etc] from "tablename" [where "condition"];The column names that follow the select keyword determine which columns will be returned in the results. You can select as many column names that you'd like, or you can use a "*" to select all columns.[] = optional
The table name that follows the keyword from specifies the table that will be queried to retrieve the desired results.
The where clause (optional) specifies which data values or rows will be returned or displayed, based on the criteria described after the keyword where.
Conditional selections used in the where clause:
=
|
Equal
|
>
|
Greater than
|
<
|
Less than
|
>=
|
Greater than or equal
|
<=
|
Less than or equal
|
<>
|
Not equal to
|
iii. Inserting into a Table
The insert statement is used to insert or add a row of data into the table.To insert records into a table, enter the key words insert into followed by the table name, followed by an open parenthesis, followed by a list of column names separated by commas, followed by a closing parenthesis, followed by the keyword values, followed by the list of values enclosed in parenthesis. The values that you enter will be held in the rows and they will match up with the column names that you specify. Strings should be enclosed in single quotes, and numbers should not.
In the example below, the column nameinsert into "tablename"(first_column,...last_column)values (first_value,...last_value);
first will match up with the value 'Luke', and the column name state will match up with the value 'Georgia'.Example:
insert into employee(first, last, age, address, city, state)values ('Luke', 'Duke', 45, '2130 Boars Nest','Hazard Co', 'Georgia');
iv. Updating Records
The update statement is used to update or change records that match a specified criteria. This is accomplished by carefully constructing a where clause.Examples:update "tablename"set "columnname" ="newvalue"[,"nextcolumn" ="newvalue2"...]where "columnname"OPERATOR "value"[and|or "column"OPERATOR "value"];[] = optional
update phone_bookset area_code = 623where prefix = 979;update phone_bookset last_name = 'Smith', prefix=555, suffix=9292where last_name = 'Jones';update employeeset age = age+1where first_name='Mary' and last_name='Williams';
v. Deleting Records
The delete statement is used to delete records or rows from the table.Examples:delete from "tablename"where "columnname"OPERATOR "value"[and|or "column"OPERATOR "value"];[ ] = optional
delete from employee;
vi. Drop a Table
The drop table command is used to delete a table and all rows in the table.To delete an entire table including all of its rows, issue the drop table command followed by the tablename. drop table is different from deleting all of the records in the table. Deleting all of the records in the table leaves the table including column and constraint information. Dropping the table removes the table definition as well as all of its rows.
Example:drop table "tablename"
drop table employee
Data Security
What is Data Security?
Data security refers to the process of protecting data from unauthorized access and data corruption throughout its life-cycle. Data security includes data encryption, tokenization, and key management practices that protect data across all applications and platforms.
Why Data Security?
Organizations around the globe are investing heavily in information technology (IT) cyber defense capabilities to protect their critical assets.
Whether an enterprise needs to protect a brand, intellectual capital, and customer information or provide controls for critical infrastructure, the means for incident detection and response to protecting organizational interests have three common elements: people, processes, and technology.
Data Security Solutions
· Cloud Access Security– Protection platform that allows you to move to the cloud securely while protecting data in cloud applications.
· Data encryption– Data-centric and tokenization security solutions that protect data across enterprise, cloud, mobile and big data environments.
· Hardware security module - Hardware security module that guards financial data and meets industry security and compliance requirements.
· Key management - Solution that protects data and enables industry regulation compliance.
· Enterprise Data Protection – Solution that provides an end-to-end data-centric approach to enterprise data protection.
· Payments Security – Solution provides complete point-to-point encryption and tokenization for retail payment transactions, enabling PCI scope reduction.
· Mobile App Security - Protecting sensitive data in native mobile apps while safeguarding the data end-to-end.
· Web Browser Security - Protects sensitive data captured at the browser, from the point the customer enters cardholder or personal data, and keeps it protected through the ecosystem to the trusted host destination.
· E-mail security– Solution that provides end-to-end encryption for email and mobile messaging, keeping Personally Identifiable Information and Personal Health Information secure and private.
What is Data warehouse
What is Data Warehousing?
A Data Warehousing (DW) is process for collecting and managing data from varied sources to provide meaningful business insights. A Data warehouse is typically used to connect and analyze business data from heterogeneous sources. The data warehouse is the core system which is built for data analysis and reporting.
It is a blend of technologies and components which aids the strategic use of data. It is electronic storage of a large amount of information by a business which is designed for query and analysis instead of transaction processing. It is a process of transforming data into information and making it available to users in a timely manner to make a difference.
Types of Data Warehouse
Three main types of Data Warehouses are:
1. Enterprise Data Warehouse:
Enterprise Data Warehouse is a centralized warehouse. It provides decision support service across the enterprise. It offers a unified approach for organizing and representing data. It also provide the ability to classify data according to the subject and give access according to those divisions.
2. Operational Data Store:
Operational Data Store, which is also called ODS, are nothing but data store required when neither Data warehouse nor OLTP systems support organizations reporting needs. In ODS, Data warehouse is refreshed in real time. Hence, it is widely preferred for routine activities like storing records of the Employees.
3. Data Mart:
A data mart is a subset of the data warehouse. It specially designed for a particular line of business, such as sales, finance, sales or finance. In an independent data mart, data can collect directly from sources.
Advantages of Data Warehouse:
- Data warehouse allows business users to quickly access critical data from some sources all in one place.
- Data warehouse provides consistent information on various cross-functional activities. It is also supporting ad-hoc reporting and query.
- Data Warehouse helps to integrate many sources of data to reduce stress on the production system.
- Data warehouse helps to reduce total turnaround time for analysis and reporting.
- Restructuring and Integration make it easier for the user to use for reporting and analysis.
- Data warehouse allows users to access critical data from the number of sources in a single place. Therefore, it saves user's time of retrieving data from multiple sources.
- Data warehouse stores a large amount of historical data. This helps users to analyze different time periods and trends to make future predictions.
Disadvantages of Data Warehouse:
- Not an ideal option for unstructured data.
- Creation and Implementation of Data Warehouse is surely time confusing affair.
- Data Warehouse can be outdated relatively quickly
- Difficult to make changes in data types and ranges, data source schema, indexes, and queries.
- The data warehouse may seem easy, but actually, it is too complex for the average users.
- Despite best efforts at project management, data warehousing project scope will always increase.
- Sometime warehouse users will develop different business rules.
- Organizations need to spend lots of their resources for training and Implementation purpose.
The Future of Data Warehousing
- Change in Regulatory constrains may limit the ability to combine source of disparate data. These disparate sources may include unstructured data which is difficult to store.
- As the size of the databases grows, the estimates of what constitutes a very large database continue to grow. It is complex to build and run data warehouse systems which are always increasing in size. The hardware and software resources are available today do not allow to keep a large amount of data online.
- Multimedia data cannot be easily manipulated as text data, whereas textual information can be retrieved by the relational software available today. This could be a research subject.
Data mining
Data mining is the process of finding anomalies, patterns and correlations within large data sets to predict outcomes.
Data mining is also called as Knowledge discovery, Knowledge extraction, data/pattern analysis, information harvesting, etc.
Data Mining Implementation Process

Business understanding:
In this phase, business and data-mining goals are established.
- First, you need to understand business and client objectives. You need to define what your client wants (which many times even they do not know themselves)
- Take stock of the current data mining scenario. Factor in resources, assumption, constraints, and other significant factors into your assessment.
- Using business objectives and current scenario, define your data mining goals.
- A good data mining plan is very detailed and should be developed to accomplish both business and data mining goals.
Data understanding:
In this phase, sanity check on data is performed to check whether its appropriate for the data mining goals.
- First, data is collected from multiple data sources available in the organization.
- These data sources may include multiple databases, flat filer or data cubes. There are issues like object matching and schema integration which can arise during Data Integration process. It is a quite complex and tricky process as data from various sources unlikely to match easily. For example, table A contains an entity named cust_no whereas another table B contains an entity named cust-id.
- Therefore, it is quite difficult to ensure that both of these given objects refer to the same value or not. Here, Metadata should be used to reduce errors in the data integration process.
- Next, the step is to search for properties of acquired data. A good way to explore the data is to answer the data mining questions (decided in business phase) using the query, reporting, and visualization tools.
- Based on the results of query, the data quality should be ascertained. Missing data if any should be acquired.
Data preparation:
In this phase, data is made production ready.
The data preparation process consumes about 90% of the time of the project.
The data from different sources should be selected, cleaned, transformed, formatted, anonymized, and constructed (if required).
Data cleaning is a process to "clean" the data by smoothing noisy data and filling in missing values.
For example, for a customer demographics profile, age data is missing. The data is incomplete and should be filled. In some cases, there could be data outliers. For instance, age has a value 300. Data could be inconsistent. For instance, name of the customer is different in different tables.
Data transformation operations change the data to make it useful in data mining. Following transformation can be applied
Data transformation:
Data transformation operations would contribute toward the success of the mining process.
Smoothing: It helps to remove noise from the data.
Aggregation: Summary or aggregation operations are applied to the data. I.e., the weekly sales data is aggregated to calculate the monthly and yearly total.
Generalization: In this step, Low-level data is replaced by higher-level concepts with the help of concept hierarchies. For example, the city is replaced by the county.
Normalization: Normalization performed when the attribute data are scaled up o scaled down. Example: Data should fall in the range -2.0 to 2.0 post-normalization.
Attribute construction: these attributes are constructed and included the given set of attributes helpful for data mining.
The result of this process is a final data set that can be used in modeling.
Modelling
In this phase, mathematical models are used to determine data patterns.
- Based on the business objectives, suitable modeling techniques should be selected for the prepared data set.
- Create a scenario to test check the quality and validity of the model.
- Run the model on the prepared data set.
- Results should be assessed by all stakeholders to make sure that model can meet data mining objectives.
Evaluation:
In this phase, patterns identified are evaluated against the business objectives.
- Results generated by the data mining model should be evaluated against the business objectives.
- Gaining business understanding is an iterative process. In fact, while understanding, new business requirements may be raised because of data mining.
- A go or no-go decision is taken to move the model in the deployment phase.
Deployment:
In the deployment phase, you ship your data mining discoveries to everyday business operations.
- The knowledge or information discovered during data mining process should be made easy to understand for non-technical stakeholders.
- A detailed deployment plan, for shipping, maintenance, and monitoring of data mining discoveries is created.
- A final project report is created with lessons learned and key experiences during the project. This helps to improve the organization's business policy.
Data mining Examples:
Example 1:
Consider a marketing head of telecom service provides who wants to increase revenues of long distance services. For high ROI on his sales and marketing efforts customer profiling is important. He has a vast data pool of customer information like age, gender, income, credit history, etc. But its impossible to determine characteristics of people who prefer long distance calls with manual analysis. Using data mining techniques, he may uncover patterns between high long distance call users and their characteristics.
For example, he might learn that his best customers are married females between the age of 45 and 54 who make more than $80,000 per year. Marketing efforts can be targeted to such demographic.
Example 2:
A bank wants to search new ways to increase revenues from its credit card operations. They want to check whether usage would double if fees were halved.
Bank has multiple years of record on average credit card balances, payment amounts, credit limit usage, and other key parameters. They create a model to check the impact of the proposed new business policy. The data results show that cutting fees in half for a targeted customer base could increase revenues by $10 million.
Benefits of Data Mining:
- Data mining technique helps companies to get knowledge-based information.
- Data mining helps organizations to make the profitable adjustments in operation and production.
- The data mining is a cost-effective and efficient solution compared to other statistical data applications.
- Data mining helps with the decision-making process.
- Facilitates automated prediction of trends and behaviors as well as automated discovery of hidden patterns.
- It can be implemented in new systems as well as existing platforms
- It is the speedy process which makes it easy for the users to analyze huge amount of data in less time.
Disadvantages of Data Mining
- There are chances of companies may sell useful information of their customers to other companies for money. For example, American Express has sold credit card purchases of their customers to the other companies.
- Many data mining analytics software is difficult to operate and requires advance training to work on.
- Different data mining tools work in different manners due to different algorithms employed in their design. Therefore, the selection of correct data mining tool is a very difficult task.
- The data mining techniques are not accurate, and so it can cause serious consequences in certain conditions.
Data Mining Applications
Applications
|
Usage
|
Communications
|
Data mining techniques are used
in communication sector to predict customer behavior to offer highly targeted and relevant campaigns. |
Insurance
|
Data mining helps insurance
companies to price their products profitable and promote new offers to their new or existing customers. |
Education
|
Data mining benefits educators
to access student data, predict achievement levels and find students or groups of students which need extra attention. For example, students who are weak in math subject. |
Manufacturing
|
With the help of Data Mining Manufacturers can predict wear and tear of production assets. They can anticipate maintenance which helps them reduce them to minimize downtime.
|
Banking
|
Data mining helps finance sector to get a view of market risks and manage regulatory compliance. It helps banks to identify probable defaulters to decide whether to issue credit cards, loans, etc.
|
Retail
|
Data Mining techniques help retail malls and grocery stores identify and arrange most sell able items in the most attentive positions. It helps store owners to comes up with the offer which encourages customers to increase their spending.
|
Service Providers
|
Service providers like mobile phone and utility industries use Data Mining to predict the reasons when a customer leaves their company. They analyze billing details, customer service interactions, complaints made to the company to assign each customer a probability score and offers incentives.
|
E-Commerce
|
E-commerce websites use Data Mining to offer cross-sells and up-sells through their websites. One of the most famous names is Amazon, who use Data mining techniques to get more customers into their eCommerce store.
|
Super Markets
|
Data Mining allows supermarket's develop rules to predict if their shoppers were likely to be expecting. By evaluating their buying pattern, they could find woman customers who are most likely pregnant. They can start targeting products like baby powder, baby shop, diapers and so on.
|
Crime Investigation
|
Data Mining helps crime investigation agencies to deploy police workforce (where is a crime most likely to happen and when?), who to search at a border crossing etc.
|
Bioinformatics
|
Data Mining helps to mine biological data from massive datasheets gathered in biology and medicine.
|
A database administrator
A database administrator (DBA) is a person who have specialized knowledge in computer systems. Who maintains a successful database environment by directing or performing all related activities to keep the data secure. The top responsibility of a DBA professional is to maintain data integrity. This means the DBA will ensure that data is secure from unauthorized access but is available to users.
Skills and Responsibilities
Typical day-to-day duties and in-demand skill sets for DBAs include the following. Database administrators:
· Implement, support and manage the corporate database.
· Design and configure relational database objects.
· Responsible for data integrity and availability.
· May design, deploy and monitor database servers.
· Design data distribution and data archiving solutions.
· Ensure database security, including backups & disaster recovery.
· Plan and implement application and data provisioning.
· Transfer database information to integrated mobile devices.
· Some database administrators design and develop the corporate database.
· Some DBAs analyze and report on corporate data to help shape business decisions.
· Produce entity relationship & data flow diagrams, database normalization schemata,
logical to physical database maps, and data table parameters.
logical to physical database maps, and data table parameters.
· Database administrators are proficient in one or more of the leading database
management systems, such as, Microsoft SQL Server, IBM DB2, MySQL and Oracle.
management systems, such as, Microsoft SQL Server, IBM DB2, MySQL and Oracle.
There are different types of DBAs depending on the organization's requirements:
- Administrative DBA – maintains the servers and databases and keeps them running. Concerned with backups, security, patches, replication. These are activities mostly geared towards maintaining the database and software platform, but not really invloved in enhancing or developing it.
- Development DBA - works on building SQL queries, stored procedures, and so on, that meet business needs. This is the equivalent of a programmer, but specializing in database development. Commonly combined the the role of Administrative DBA.
- Data Architect – designs sachems, builds tables indexes, data structures and relationships. This role works to build a structure that meets a general business needs in a particular area. For instance, a software company will use data architects to build a design for the database of a new commercial application system for running a bank's operations. The design is then used by developers and development DBAs to implement the actual application.
· Data Warehouse DBA - this is a relatively newer role, responsible for merging data from multiple sources into a data warehouse. May have to design the data warehouse as well as cleaning up and standardizing the data before loading using specialist data loading and transformation tools.


0 Comments